隨著人工智慧(AI)和大型語言模型(LLM)技術的快速發展,企業對 AI 工作負載的部署和管理需求日益增長。然而,AI POD 環境的複雜性,包括分散式運算、高效能 GPU、大量資料儲存和複雜的網路互聯,為其效能監控、成本優化和故障排除帶來了巨大挑戰。思科 Splunk Observability Cloud for AI POD 解決方案旨在應對這些挑戰,為企業提供全面的可見度和智慧洞察。
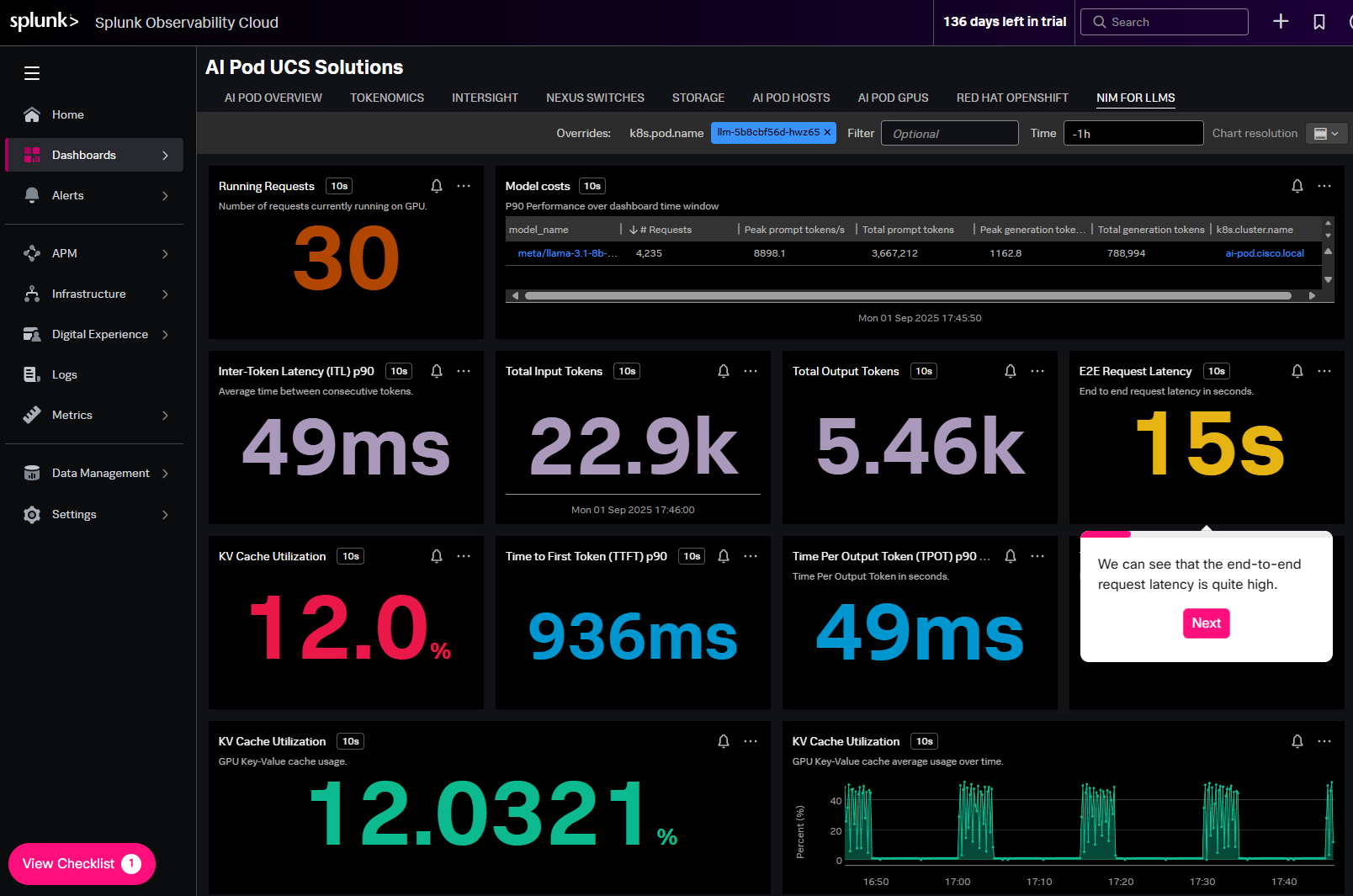
核心痛點解決此解決方案專注於解決 AI POD 營運中的核心痛點: 1.效能瓶頸辨識:快速定位 AI 模型推理和訓練過程中的效能瓶頸,如高延遲、GPU 使用率低或過高、以及 Token 生成速度慢等問題。 2.資源成本最佳化:有效管理和優化 AI 基礎架構的資源消耗,特別是 GPU、儲存和網路資源,以及 LLM 的 Token 使用成本(即「Tokenomics」)。 3.複雜環境的視覺化:將分散的 AI 基礎設施元件(如運算主機、網路、儲存、容器平台)統一到一個平台進行監控,消除盲點。 4.快速故障排除:透過即時數據和智慧告警,加速問題診斷和解決,減少 AI 服務的停機時間。
端對端的監控能力Splunk Observability Cloud for AI POD 解決方案整合了多項關鍵技術與專用模組,提供端對端的監控能力: ◎ AI POD Overview:提供 AI POD 整體健康狀況和關鍵效能指標的概覽,例如目前運作的請求數量。 ◎ Tokenomics:針對 LLM 工作負載的核心模組,監控 Token 的使用效率和成本。它詳細顯示了總輸入 Token、總輸出 Token、峰值提示 Token / 秒、峰值生成 Token / 秒等指標,幫助用戶理解和優化 LLM 的運行成本和吞吐量。 ◎ Intersight:與 Cisco Intersight 集成,用於監控和管理底層的 Cisco UCS 伺服器和 HyperFlex 超融合基礎設施,確保運算資源的穩定性和效率。 ◎ Nexus Switches:監控 Cisco Nexus 資料中心交換器的網路效能,確保 AI POD 內部外部資料傳輸的低延遲和高頻寬,這對於處理大量資料的 AI 應用至關重要。 ◎ Storage:提供對儲存系統效能的深度洞察,包括 I/O 延遲、吞吐量和容量使用情況,確保 AI 模型訓練和推理所需資料的快速存取。 ◎ AI POD Hosts & AI POD GPUs:專注於 AI 運算核心-主機與 GPU 的效能。監控 GPU 的關鍵指標,如 KV Cache 使用率,以及 GPU 的整體健康狀況和效能表現。 ◎ Red Hat OpenShift:支援對運行在 OpenShift 容器平台上的 AI 應用進行監控,確保容器化 AI 服務的穩定運作和資源調度效率。 ◎ 針對 NVIDIA LLM 推理微服務的特定監控,優化 LLM 的推理性能,包括關注如首次 Token 生成時間(TTFT)和每 Token 輸出時間(TPOT)等關鍵延遲指標。
Splunk Observability Cloud for AI POD 解決方案為企業提供了一個統一、智慧的平台,以應對 AI 時代複雜的維運挑戰,確保 AI 投資能夠轉化為實實在在的業務價值。 自助展示網站:https://cisco-full-stack-observability.navattic.com/2sk0bvw