「全球大宕機」的始作俑者究竟是什麼公司?
來源|華爾街見聞
作者|黃雯雯
7月19日週五,微軟系統發生了全球大宕機事故,市場陷入混亂,多家企業的營運出現問題,全球供應鏈也受打擊,在歐亞和北美的全球最大航空貨運樞紐,數千架航班停飛或延誤,航空運輸可能需要幾週才能恢復正常。事件背後的「罪魁禍首」CrowdStrike 因此成為了焦點。
據媒體報道,近日全球範圍內的電腦系統崩潰是由於CrowdStrike Falcon版本更新的一個問題造成的。
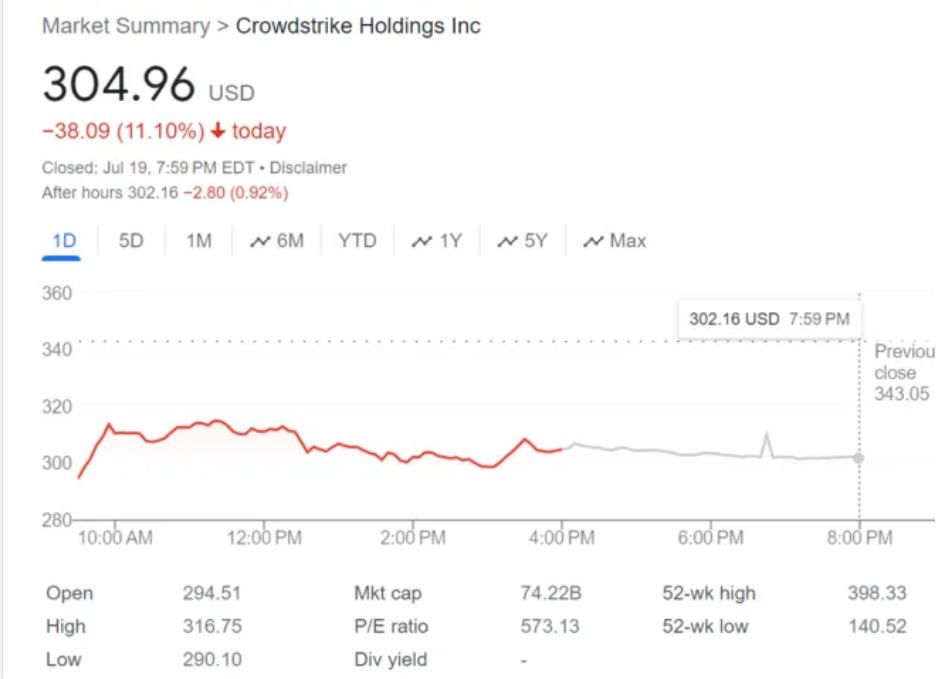
當地時間週五,美股盤初,CrowdStrike股價一度大跌14%,收跌11.1%,報每股304.96美元,市值一夜蒸發近百億美元,創2022年以來最差單日表現。值此之
際,「木頭姐」Cathie Wood管理的ARK ETF也大手筆抄底。
那麼這個「全球大宕機」的始作俑者究竟是什麼公司?如何影響微軟並造成如此大的殺傷力的?
CrowdStrike是什麼公司?
據介紹,CrowdStrike是一家提供線上安全解決方案的公司,專注於提供基於雲端運算的端點保護平台。公司成立於2011年,總部位於美國加州,CrowdStrike的主要產品是Falcon平台,它利用人工智慧和機器學習技術來偵測、預防和回應網路威脅。
CrowdStrike是美國的網路安全龍頭公司,因其在偵測和防禦高級網路攻擊方面的能力而聞名,世界500強企業中有271家是其客戶,其軟體被包括微軟、亞馬遜AWS在內的一些最大的雲端服務公司供應商所使用,也包括主要的全球銀行、醫療保健和能源公司,幫助它們檢測並阻止駭客威脅,許多政府機構(例如美國頂級的網路安全機構和基礎設施安全局)也使用其軟體。
據市場研究機構IDC稱,在價值86億美元的「端點偵測與回應」(EDR)軟體市場中,CrowdStrike佔比重約18%,僅次於微軟。
CrowdStrike如何導致藍屏?微軟為何捲入其中?
CrowdStrike提供的軟體類型有別於舊式的、版本有限的安全軟體,傳統的防毒軟體在電腦和網路發展初期效果顯著,因為它能夠捕捉已知惡意軟體的跡象,但隨著攻擊變得越來越複雜,這種軟體已經不再受歡迎。
現在,CrowdStrike開發的被稱為「端點偵測和回應」軟體的產品比傳統防毒軟體有效得多,但與其他網路安全產品一樣,CrowdStrike的軟體需要更深層地存取電腦的作業系統來掃描威脅,而這種存取權限使其有能力破壞它們試圖保護的系統。
微軟和CrowdStrike是競爭對手,兩家提供的「端點」網路安全產品類似,CrowdStrike的Falcon平台可以與微軟的安全產品集成,如Microsoft Azure和Microsoft 365,以增強整體網路安全防護能力。
據報道,昨天的事故或源自於CrowdStrike發布的軟體程式碼更新與Windows系統的互動方式有誤而崩潰,導致大量用戶出現「藍屏死機」。
CrowdStrike的聯合創始人兼首席執行官George Kurtz承認了這個問題,並表示已經部署了修復措施:
“CrowdStrike正在積極與受影響的客戶合作,解決在Windows主機上發現的單一內容更新中的缺陷。Mac和Linux主機不受此影響。這不是一起安全事件或網路攻擊。”
CrowdStrike殺傷力有多廣?
CrowdStrike一個錯誤的軟體更新導致航空、銀行、醫療保健、零售等行業客戶出現連環故障,港口、企業和政府都受到影響。醫院被迫推遲了手術,麥當勞、UPS和聯邦快遞也因此故障。摩根大通、野村控股和美銀等銀行的員工週五無法登入公司係統。
對航空公司而言,這次故障導致飛機和地面控制台溝通遇阻,旅客出行受到影響。 FlightAware顯示全球超過21,000個航班延誤。目前,美聯航、達美航空、 美國航空、漢莎航空、法荷航、瑞安航空正在逐步恢復,但速度緩慢。
供應鏈諮詢公司 Xeneta 的首席空運官 Niall van de Wouw 在與聲明中表示:
「飛機和貨物不在它們應該在的地方,(這個問題)需要幾天甚至幾週的時間才能完全解決。它提醒大家,我們的海運和空運供應鏈面對IT 故障是多麼不堪一擊。”
網路安全專業人士稱,
CrowdStrike的技術是抵禦勒索軟體的有力手段,但其成本(在某些情況下每台機器可能超過50美元),意味著大多數企業不會在所有電腦上安裝,而安裝了該軟體的電腦是最需要保護的計算機,如果它們癱瘓,關鍵服務也會跟著癱瘓。
倫敦大學學院電腦科學系助理教授Marie Vasek表示,
「大範圍的電腦崩潰表明,全球技術系統對少數公司的軟體有多麼依賴,包括微軟和CrowdStrike的軟體。這裡的問題是,微軟是每個人都使用的標準軟體,CrowdStrike中的漏洞被部署到每個系統中。
CrowdStrike還稱,由於該公司在作業系統和生產力軟體方面的市場主導地位,其任何弱點都可能帶來潛在的災難性的影響。
值得注意的是,這次全球性IT技術故障也導致特斯拉暫停了某些生產線。 7月20日北京時間凌晨1:10分左右,據媒體報道,特斯拉因CrowdStrike造成全球性IT技術故障而暫停某些生產線,公司員工尚未被告知何時才能復工復產。此前北京時間凌晨0:28分左右,馬斯克稱,“我們剛剛從所有系統中刪除了CrowdStrike。”
問題如何解決?誰來承擔損失?
CrowdStrike執行長George Kurtz稱,問題癥結已經找到,公司部署了修復程序。除Mac和Linux機器外,任何受到該更新影響而當機的Windows桌上型電腦或筆記型電腦都需要再次更新。
根據媒體引述的CrowdStrike與一位客戶的溝通中,CrowdStrike的技術支援團隊建議說,可能需要將受影響的系統重啟多達15次。
保險經紀公司Marsh McLennan稱,超過75家客戶可能會因為CrowdStrike全球性崩潰事件而提出網路故障索賠。
而對於故障造成的經濟損失程度以及誰會承擔這些損失,在一段時間內還不得而知。據悉,大多數軟體供應商對其程式造成的損害不承擔法律責任,這些程式是授權的,而非出售的。但他們通常與最大的客戶簽訂了服務協議,可能需要幫助補救、給予折扣或其他補償。
CrowdStrike 在聲明中表示,
“正在與所有受影響的客戶合作,以確保系統恢復正常運行,並能提供客戶所期望的服務。”
另外,值得注意的是,還有一起涉及微軟Azure雲端服務的事件也造成了服務中斷。微軟表示,已經解決了根本問題,但用戶仍然會感受到「殘餘影響」。
有分析稱,目前還不清楚電腦系統崩潰有多少是由 CrowdStrike 軟體更新缺陷引起的,有多少是由周四開始的微軟線上服務及其企業雲端運算服務 Azure 出現的問題引起的。
但微軟發言人稱,該公司不認為 CrowdStrike 軟體漏洞與影響「部分 Azure 客戶」的中斷有關。
華爾街怎麼看?
分析師的態度也各異,Wedbush Securities分析師Dan Ives表示:
「這對CrowdStrike來說顯然是一個重大的打擊,該股將面臨壓力。…這一事件源於技術更新,而不是駭客或網路安全威脅,這將更令人擔憂。”
也有分析師認為,雖然週五的事件對CrowdStrike造成了損害,但他們預計競爭對手不會因此事件而奪走太多市場份額。摩根大通的分析師表示:
“客戶最初會感到不安,但該公司已經接管了這一問題…故障發生了,而且規模很大,但我們認為CrowdStrike的盡職盡責和高效反應將有所幫助。”
前網路安全投資者、現經營安全新創公司Gusto的Ben Bernstein表示,他計劃暫時繼續使用CrowdStrike。
值得注意的是,全球宕機引發暴跌之際,「木頭姐」大手筆「抄底」CrowdStrike,當地時間7月19日,木頭姐姐旗下方舟投資透過其ARKW和ARKF ETF逆勢買入了價值約1324萬美元的38595股CrowdStrike股票。