Route就是用來顯示、新增、刪除和修改路由的指令,我們先來看用法。
一、route指令的格式與參數它的格式如下:
route [-f] [-p] [Command [Destination] [mask Netmask] [Gateway] [metric Metric]] [if Interface]]
單看這個語法,我們可能並不熟悉,我們來詳細了解它的參數的意思。
其中 :–f:參數用於清除路由表。 -p:參數用於永久保留某條路由(即係統重新啟動時不會遺失路由)
Command:主要有PRINT(列印)、ADD(新增)、DELETE(刪除)、CHANGE:(修改)共4個指令。
Destination:代表所要達到的目標IP位址。
MASK:是子網路遮罩的關鍵字。
Netmask:代表特定的子網路掩碼,如果不加說明,預設是255.255.255.255(單機IP位址),因此鍵入遮罩時候要特別小心,要確認新增的是某個IP位址還是IP網段。
若代表全部出口子網路遮罩可用0.0.0.0。
Gateway:代表出口網關。
其他interface和metric分別代表特殊路由的介面數目和到達目標位址的代價,一般可不予理會。我們根據單網卡和多網卡(以雙網卡為例)兩種情況敘述在WINDOWS下如何具體設定路由。
二、route指令用法範例
上面我們已經了解了關於route指令的格式與參數意思,那麼它們是如何使呢?
我們起來看下。
1、要顯示 IP 路由表的完整內容,請鍵入:route print
2、若要顯示 IP 路由表中以 10. 開始的路由,請鍵入:route print 10.*
3.要新增預設閘道位址為 192.168.12.1 的預設路由,請鍵入:route add 0.0.0.0 mask 0.0.0.0 192.168.12.1
4.要新增目標為 10.41.0.0,子網路遮罩為 255.255.0.0,下一個躍點位址為 10.27.0.1 的路由,請鍵入:route add 10.41.0.0 mask 255.255.0.010.
5.要新增目標為 10.41.0.0,子網路遮罩為 255.255.0.0,下一個躍點位址為 10.27.0.1 的永久路由,請鍵入:route -p add 10.41.0.0 mask 255.255.0.010.
6、要新增目標為 10.41.0.0,子網路遮罩為 255.255.0.0,下一個躍點位址為 10.27.0.1,躍點數為 7 的路由,請鍵入:route add 10.41.0.0 mask 255.255.
7.要新增目標為 10.41.0.0,子網路遮罩為 255.255.0.0,下一個躍點位址為 10.27.0.1,介面索引為 0x3 的路由,請鍵入:route add 10.41.0.0 mask 255.25.
8.要刪除目標為 10.41.0.0,子網路遮罩為 255.255.0.0 的路由,請鍵入:route delete 10.41.0.0 mask 255.255.0.0
9.要刪除 IP 路由表中以 10. 開始的所有路由,請鍵入:route delete 10.*
10.要將目標為 10.41.0.0,子網路遮罩為 255.255.0.0 的路由的下一個躍點位址由 10.27.0.1 改為 10.27.0.25,請鍵入:route change 10.41.0.0 mask.
三、route指令:實現雙網卡同時使用有線上內網,無線上外網在我們做專案時,經常可能會用到外網與內網切換使用,這樣就造成了插拔網線在切換內外網,極其麻煩,這個在我們弱電vip技術群中經常有朋友和上網
例如:筆記本上一張機械網卡,一張無線網卡, 一般筆記本都是這樣的配置,都聯上了內外與外網,其中外網網關是49.222.151.207,內網網關10.168.1.1,如何實現雙網卡同時使用有線上網內網、無線網外網?
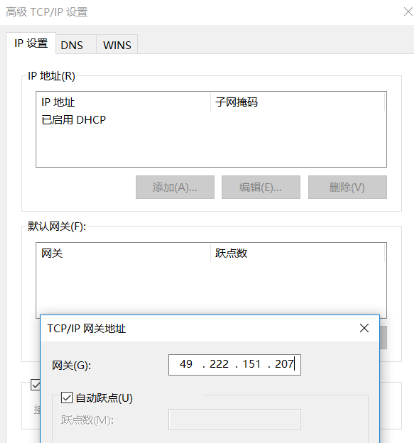
第一步:设置无线网卡为默认路由网关。
步骤:无线网络连接属性—Internet协议(TCP/IP)-属性-高级,手动添加无线路由网关,添加自己的外网网关即关,跃点数为“1”,是最高优先级。到了这一步,如果有线连接,无线连接同时存在的话,所有的数据都是经由无线网卡处理的。
第二步:查看当前路由表
使用route print命令看一个0.0.0.0的网络目标分别映射你的外内网的网关。
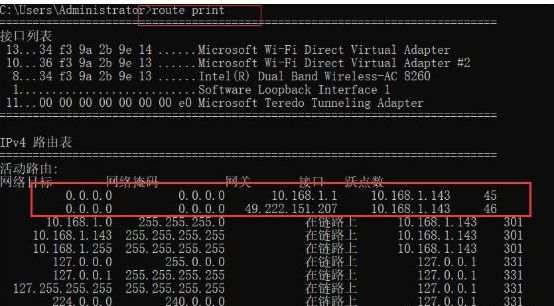
当然,这里面你也可以对当前的路由进行删除

第三步:
通过route命令将,将所有网段添加到外网网卡,为默认路由,即所有的ip都走外网。

显示查看路由表,查看是否添加成功。

第四步:
通过route命令将内网网段添加到内网网卡,内网使用,即10.168.0.0这个ip段走内网。

显示查看路由表(route print命令),查看是否添加成功。
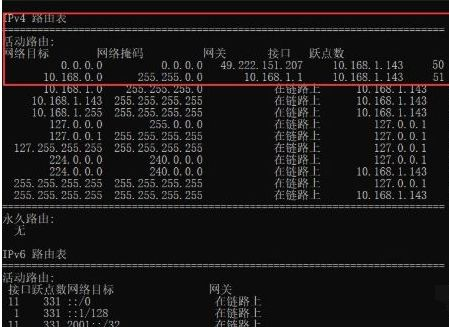
那麼就設定成功了,整體的意思就是:對於所有IP位址的訪問,都從 49.222.151.207網關走;但是,對於10.168.0.0開頭的位址的訪問,從10.168.1.1走。
這樣,再也不用插拔網路線這種粗魯的方式來切換網路了。
補充:
1.為了加強大家的理解,弱電君補充一個小案例,如果在電腦接線時訪問不了“10.26.6.x”開頭的ip地址,但使用無線wifi卻可以訪問?如何解決?增加一個路由規定10.26.6.x網段都走本地連線的閘道:route -p add 10.26.6.0 mask 255.255.255.0 10.168.1.1 這條指令的作用是新增一條永久路由規則(如果不加「-p」參數則為臨時路由,註銷下次登入windows時就沒有了),凡是存取「10.26.6.x」開頭並且掩碼是255.255.255.0的ip.10.168.明白原理了無論什麼路由新增與刪除都可以輕鬆設定了。 2.如果你不知道各網路介面的IP位址、網關位址,可以透過ipconfig/all指令取得。

