重傳機制
超時重傳
重送機制的其中一個方式,就是在發送資料時,設定一個定時器,當超過指定的時間後,沒有收到對方的 ACK 確認應答報文,就會重發該資料超時觸發重傳存在的問題是,超時週期可能相對較長。
快速重傳
快速重傳不以時間為驅動,而是以數據驅動重傳。
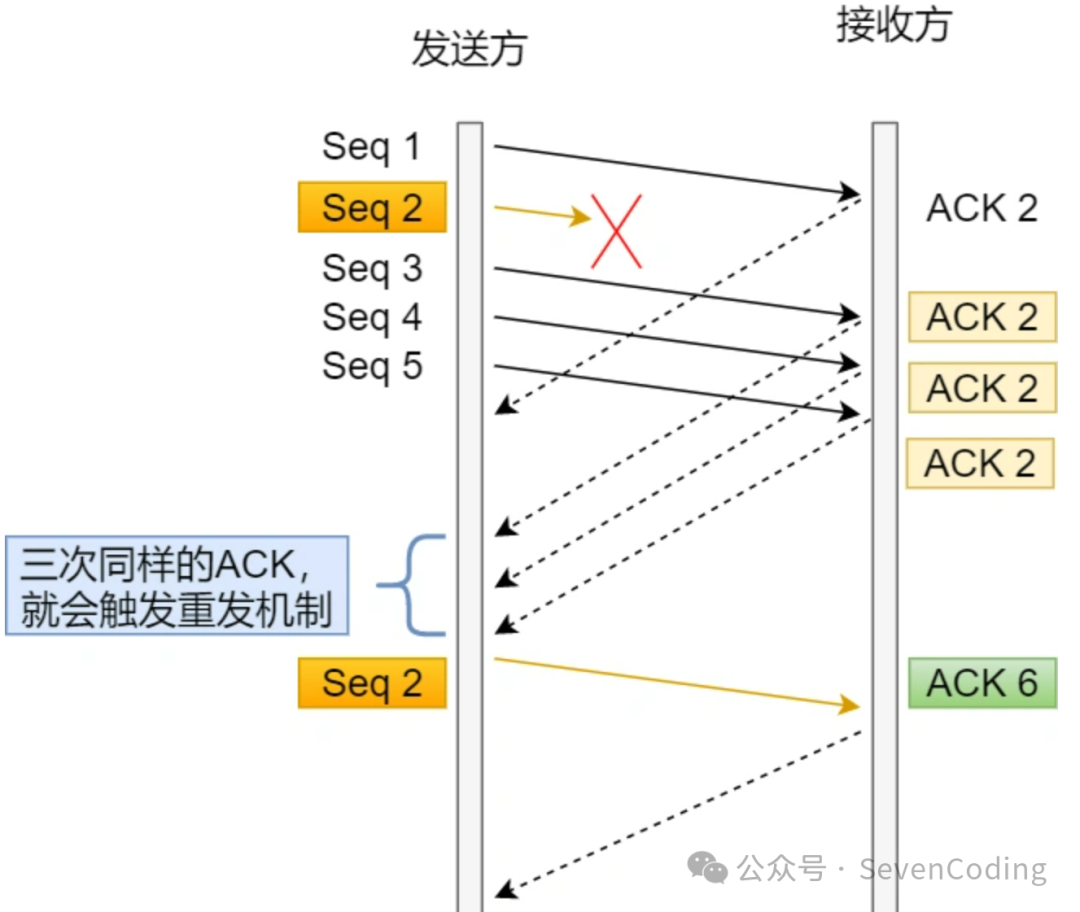
快速重傳的工作方式是當收到三個相同的 ACK 報文時,可以不用等到超時才重傳,會直接重傳遺失的報文段。快速重傳機制只解決了一個問題,就是超時時間的問題,但它依然面臨另一個問題。
就是重傳的時候,是重傳一個,還是重傳所有的問題舉個例子,假設發送方發了 6 個數據,編號的順序是 Seq1 ~ Seq6 ,但是 Seq2、Seq3 都丟失了,那麼接收方在收到 Seq4、Seq5、Seq6 時,都是回复 ACK2 給發送方,但是之後已發送的所有報文呢(Seq2、Seq3、 Seq4、Seq5、 Seq6) 呢?
SACK 方法
SACK( Selective Acknowledgment), 選擇性確認。 SACK是將已收到的資料的訊息傳送給發送方,這樣發送方就可以只重傳遺失的資料。
如下圖,發送方收到了三次相同的 ACK 確認報文,於是就會觸發快速重發機制,透過 SACK 訊息發現只有 200~299 這段資料遺失,則重發時,就只選擇了這個 TCP 段進行重複。

Duplicate SACK
要使用了 SACK 來告訴「傳送者」有哪些資料被重複接收了。
滑動視窗
TCP 每發送一個數據,都要進行一次確認應答。
當上一個資料包收到了應答了, 再發送下一個。
如果是這樣傳輸,那有一個缺點:封包的往返時間越長,通訊的效率就越低。
因此,TCP引入了滑動視窗。視窗大小就是指無需等待確認應答,而可以繼續傳送資料的最大值。
視窗中有部分資料段沒有收到ACK,也可以透過下一個ACK確認。這個模式就叫累計確認或累計應答。
視窗的大小是由接收方的視窗大小決定的。
發送方傳送的資料大小不能超過接收方的視窗大小,否則接收方就無法正常接收到資料。
接收視窗的大小是約等於發送視窗的大小的。因為滑動視窗並不是一成不變的。
例如,當接收方的應用程式讀取資料的速度非常快的話,這樣的話接收視窗可以很快的就空缺出來。
那麼新的接收視窗大小,就是透過 TCP 封包中的 Windows 欄位來告訴發送方。那麼這個傳輸過程是存在時延的,所以接收視窗和發送視窗是約等於的關係。
MSS限制
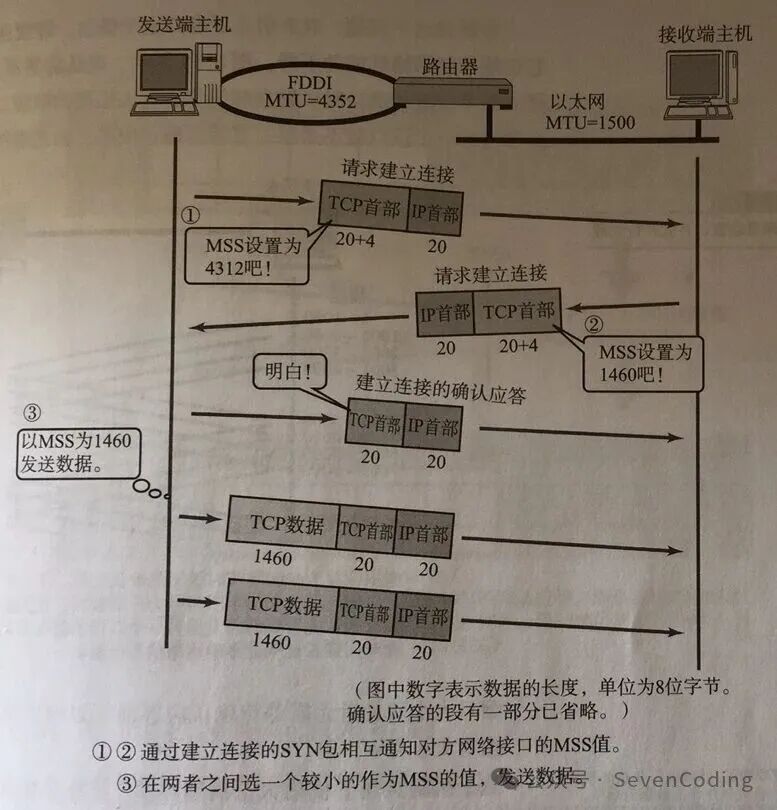
鏈路層對一次能夠發送的最大資料有限制,這個限制稱為 MTU(maximum transmission unit),不同的鏈路設備的 MTU 值也有所不同,例如乙太網路的 MTU 是 1500FDDI(光纖分散式資料介面)的 MTU 是 4352 本地回環位址的 MTU 是本地回環位址size),它是 MTU 刨去 tcp 頭和 ip 頭後剩餘能夠作為資料傳輸的位元組數ipv4 tcp 頭佔用 20 bytes,ip 頭佔用 20 bytes,因此乙太網路 MSS 的值為 1500 – 40 = 1460TCP 將大量資料傳送時,將大量資料傳送至 MSS 的資料在 MSS.的值,然後在兩者之間選擇一個小值作為 MSS
TCP黏包
黏包的問題出現是因為不知道一個用戶訊息的邊界在哪,如果知道了邊界在哪,接收方就可以透過邊界來分割出有效的用戶訊息。
出現黏包的原因是多方面的,可能是來自接收方,也可能是來自發送方。
發送方原因
因為即使傳送一個字節,也需要加入 tcp 頭和 ip 頭,也就是總字節數會使用 41 bytes,非常不經濟。
因此Nagle演算法試圖在發送一個分組之前,將大量的TCP資料綁定在一起,以提高網路效率。
該演算法是指發送端即使還有應該發送的數據,但如果這部分數據很少的話,則進行延遲發送如果 SO_SNDBUF 的數據達到 MSS,則需要發送如果 SO_SNDBUF 中含有 FIN(表示需要連接關閉)這時將剩餘數據發送,再關閉如果 TCP_NODELAY = true,則需要發送已發送關閉)這時將剩餘數據發送,再關閉如果 TCP_NODELAY = true,則需要發送已發送已發送的數據都需要發送時,但上述條件200ms)則需要發送除上述情況,延遲發送TCP預設使用Nagle演算法(主要作用:減少網路中報文段的數量),而Nagle演算法主要做兩件事:只有上一個分組得到確認,才會發送下一個分組收集多個小分組,在一個確認到來時一起發送。
Nagle演算法造成了發送方可能會出現黏包問題。對於發送方造成的黏包問題,可以透過關閉Nagle演算法來解決,使用TCP_NODELAY選項來關閉演算法。
接收方原因
TCP接收到封包時,並不會馬上交到應用層處理,或是應用層並不會立即處理。
實際上,TCP將接收到的資料包保存在接收快取裡,然後應用程式主動從快取讀取收到的分組。
這樣一來,如果TCP接收資料報到快取的速度島嶼應用程式從快取中讀取資料報的速度,多個包就會被緩存,應用程式就有可能讀取到多個收尾相接黏在一起的包。
接收方沒有辦法處理黏包問題,只能將問題交給應用層來處理
解決方式
一般有三种方式分包的方式(可以同时解决发送方和接收方的问题):
- 固定长度的消息:这种是最简单方法,即每个用户消息都是固定长度的,比如规定一个消息的长度是 64 个字节,当接收方接满 64 个字节,就认为这个内容是一个完整且有效的消息
- 特殊字符作为边界:比如HTTP 通过设置回车符、换行符作为 HTTP 报文协议的边界。
- 自定义消息结构,如TLV 格式,即 Type 类型、Length 长度、Value 数据,类型和长度已知的情况下,就可以方便获取消息大小,分配合适的 buffer,缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量
- Http 1.1 是 TLV 格式
- Http 2.0 是 LTV 格式
流量控制
发送方不能无脑的发数据给接收方,要考虑接收方处理能力。
流量控制就是根据接收方的滑动窗口的大小来控制的。
比如服务端繁忙,无法及时的处理掉接收的数据,就会减小接收窗口的大小
拥塞控制
流量控制是避免「发送方」的数据填满「接收方」的缓存
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环
拥塞控制,目的就是避免「发送方」的数据填满整个网络。
拥塞控制是根据拥塞窗口来实现的,拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的
发送方没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞。
慢启动
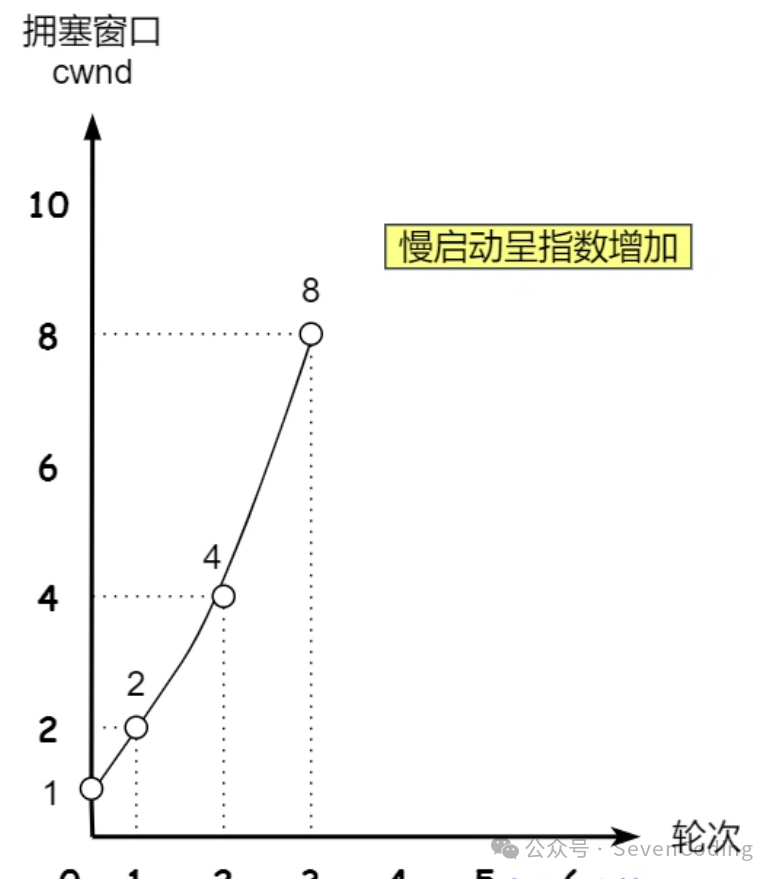
慢启动算法:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
这个大小是指能同时发送数据的数量,比如一开始拥塞窗口为1,表示可以传1个;发送方收到一个 ACK 确认应答后,cwnd 增加 1,于是一次能够发送 2 个;以此类推,显然慢启动时的拥塞窗口大小是呈指数增长的
一般有三种方式分包的方式(可以同时解决发送方和接收方的问题):
- 固定长度的消息:这种是最简单方法,即每个用户消息都是固定长度的,比如规定一个消息的长度是 64 个字节,当接收方接满 64 个字节,就认为这个内容是一个完整且有效的消息
- 特殊字符作为边界:比如HTTP 通过设置回车符、换行符作为 HTTP 报文协议的边界。
- 自定义消息结构,如TLV 格式,即 Type 类型、Length 长度、Value 数据,类型和长度已知的情况下,就可以方便获取消息大小,分配合适的 buffer,缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量
- Http 1.1 是 TLV 格式
- Http 2.0 是 LTV 格式
流量控制
发送方不能无脑的发数据给接收方,要考虑接收方处理能力。
流量控制就是根据接收方的滑动窗口的大小来控制的。
比如服务端繁忙,无法及时的处理掉接收的数据,就会减小接收窗口的大小
拥塞控制
流量控制是避免「发送方」的数据填满「接收方」的缓存
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环
拥塞控制,目的就是避免「发送方」的数据填满整个网络。
拥塞控制是根据拥塞窗口来实现的,拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的
发送方没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞。
慢启动
慢启动算法:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
这个大小是指能同时发送数据的数量,比如一开始拥塞窗口为1,表示可以传1个;发送方收到一个 ACK 确认应答后,cwnd 增加 1,于是一次能够发送 2 个;以此类推,显然慢启动时的拥塞窗口大小是呈指数增长的
慢启动算法增长到哪是根据慢启动门限 ssthresh (slow start threshold)来决定的:
- 当 cwnd < ssthresh 时,使用慢启动算法。
- 当 cwnd >= ssthresh 时,就会使用拥塞避免算法
拥塞避免
拥塞避免算法:每当收到一个 ACK 时,cwnd 增加 1/cwnd。
现假定 ssthresh 为 8,当到门限时,当 8 个 ACK 应答确认到来时,每个确认增加 1/8,8 个 ACK 确认 cwnd 一共增加 1
就这么一直增长着后,网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。当触发了重传机制,也就进入了拥塞发生算法
拥塞发生
当网络出现拥塞,也就是会发生数据包重传,重传机制主要有两种,两种使用的拥塞发送算法是不同的
- 超时重传
- 快速重传
超时重传
- ssthresh 设为 cwnd/2
- cwnd 重置为 1 (是恢复为 cwnd 初始化值,我这里假定 cwnd 初始化值 1)
接着,就重新开始慢启动,慢启动会突然减少数据流,
快速重传
当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。https://wxa.wxs.qq.com/tmpl/pr/base_tmpl.html
- cwnd = cwnd/2 ,也就是设置为原来的一半;
- ssthresh = cwnd;
进入快速恢复算法
快速恢复
算法如下:
- 拥塞窗口 cwnd = ssthresh + 3 ( 3 的意思是确认有 3 个数据包被收到了);
- 重传丢失的数据包;
- 如果再收到重复的 ACK,那么 cwnd 增加 1; 如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
也就是没有像「超时重传」一夜回到解放前,而是还在比较高的值,后续呈线性增长