【摘要】隨著大模型的興起,GPU算力的需求越來越多,而當前現實狀況使企業往往受限於有限的GPU卡資源,即便進行了虛擬化,往往也難以充分使用GPU卡資源或持續使用資源。為解決GPU算力資源不均衡等問題,同時支援GPU算力的國產化替代,提升GPU資源的使用率,GPU算力池化需求迫在眉睫。
本文分享了GPU設備虛擬化的幾種路線、GPU虛擬化與共享方案以及GPU算力池化雲端原生實作。
【作者】汪照輝,中國銀河證券架構師,專注於容器雲、微服務、DevOps、資料治理、數位轉型等領域,對相關技術有獨特的理解與見解。擅長於軟體規劃和設計,提出的「平台融合」的觀點越來越被認同和事實證明。發表了許多技術文章探討容器平台建置、微服務技術、DevOps、數位轉型、資料治理、中台建置等內容,受到了廣泛關注與肯定。
智慧化應用如人臉辨識、語音辨識、文字辨識、智慧推薦、智慧客服、智慧風控等已廣泛應用於各行各業,這些應用被稱為判定式AI的範疇,通常和特定的業務場景相綁定,因此在使用GPU(Graphics Processing Unit)卡的時候也通常各自獨立,未考慮業務間GPU共享能力,至多實現vGPU虛擬化切分,從而一張實體GPU卡虛擬出多張vGPU,可以運行多個判定式AI 應用。隨著大模型的興起,對GPU算力的需求越來越多,而當前現實情況使企業往往受限於有限的GPU卡資源,難以支撐眾多的業務需求,同時由於業務特性等,即便進行了虛擬化,往往難以充分使用GPU卡資源或持續使用資源,因此也造成有限的卡片資源也無法有效利用。
從GPU虛擬化需求到池化需求智慧化應用數量的成長對GPU算力資源的需求越來越多。 NVIDIA雖然提供了GPU虛擬化和多GPU執行個體切分方案等,但仍無法滿足自由定義虛擬GPU和整個企業GPU資源的共享重複使用需求。 TensorFlow、Pytorch等智慧化應用框架開發的應用往往獨佔一張GPU整卡(AntMan框架是為共享的形式設計的),從而使GPU卡短缺,另一方面,大部分應用卻只使用卡的一小部分資源,例如身分證辨識、票據辨識、語音辨識、投研分析等推理場景,這些場景GPU卡的使用率都比較低,沒有業務請求時利用率甚至是0%,有算力卻受限於卡的有限數量。
單一推理場景佔用一張卡片造成很大浪費,和卡片數量不足形成矛盾,因此,算力切分是目前許多場景的基本需求。再者,往往受限於組織架構等因素,GPU由各團隊自行採購使用,算力資源形成孤島,分佈不均衡,有的團隊GPU資源空閒,有團隊無卡可用。為解決GPU算力資源不均衡等問題,同時支援GPU算力的國產化替代,協調線上和離線資源需求、業務高峰和低峰值資源需求、訓練和推理、以及開發、測試、生產環境對資源需求不同,實現算力的統一管理與調度重複使用,實現GPU資源的切分、聚合、超分、遠端呼叫、應用熱遷移等能力,提升GPU資源的利用率,GPU算力池化需求迫在眉睫。
GPU設備虛擬化路線GPU設備虛擬化有幾個可行方案。
首先是PCIe直通模式(PCIe Pass-through技術,pGPU),也就是將實體主機上的整塊GPU卡直通掛載到虛擬機器上使用。但這種方式是獨佔模式,GPU卡沒有虛擬化切分,並不能解決多個應用運行在一張卡上的問題,因此意義不是很大。
第二是採用SR-IOV技術,讓一個PCIe設備在多個虛擬機器之間共享,同時保持較高效能。透過SR-IOV在實體GPU設備上創建多個虛擬vGPU來實現的,每個虛擬vGPU可以被分配到一個虛擬機,讓虛擬機直接存取和控制這些虛擬功能,從而實現高效的I/O虛擬化。 NVIDIA早期的vGPU就是這樣的實現,不過NVIDIA vGPU需要額外的license,額外增加了成本。SR-IOV雖然實現了1:N的能力,但其彈性比較差,難以更細粒度的分割和調度。
第三是MPT(Mediated Pass-Through,受控制的直通)模式。 MPT本質上是一種通用的PCIe設備虛擬化方案。兼顧了1:N靈活性、高性能、功能完整性,但邏輯上相當於實現在內核態的device-model,廠商通常不會公開硬體編程接口,因此採用MPT可能會形成廠商依賴。用的最多的模式是API轉送模式。根據AI應用的呼叫層次(如下圖),API轉送有多個層次,包含CUDA API轉送(圖中①)、GPU Driver API轉送(圖中②)和裝置硬體層API轉送(圖③)。設備硬體層API通常是難以取得的,因此目前市面上通常採用CUDA API轉送模式(截獲CUDA請求轉發,也稱為用戶態)和GPU卡驅動Driver API轉送模式(截取驅動層請求轉發,也被稱為內核態).另外AI開發框架往往和GPU卡綁定(例如華為支持CANN框架,海光支持DTK框架,英偉達則支持TensorFlow、Pytorch等框架),AI應用在使用AI框架時,也可以在AI框架層進行轉發,在AI應用程式遷移時比較有用。
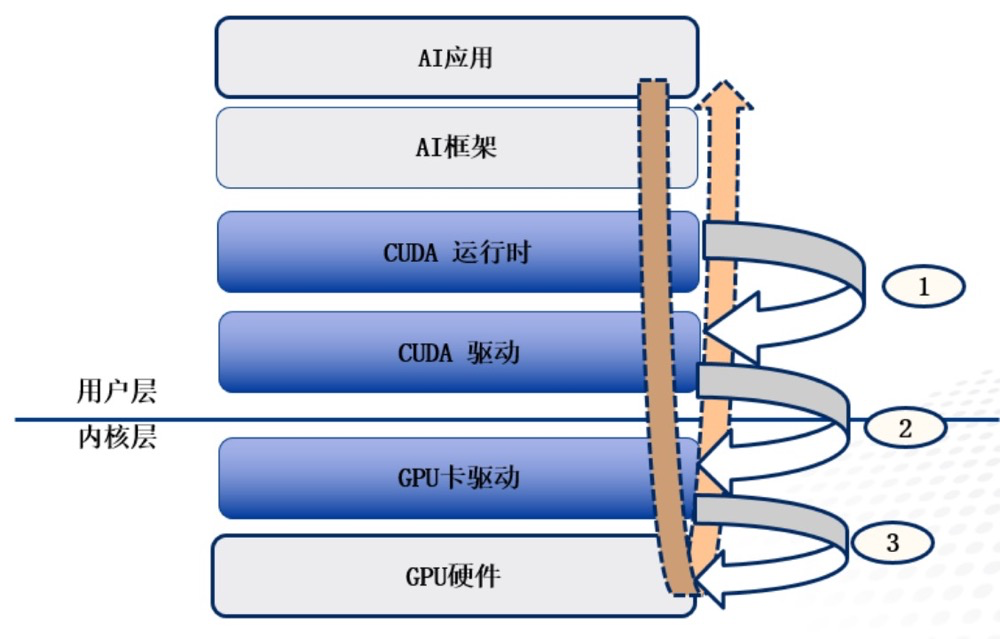
AI應用呼叫層次
GPU虛擬化與共享方案了解了GPU設備虛擬化的方式,基於裝置虛擬化技術,看下GPU虛擬化與共享的實作方式。 GPU虛擬化和共享有多種方案,英偉達從官方也提供了vGPU、MIG、MPS等方案,以及非官方的vCUDA、rCUDA、核心劫持等多種方案。
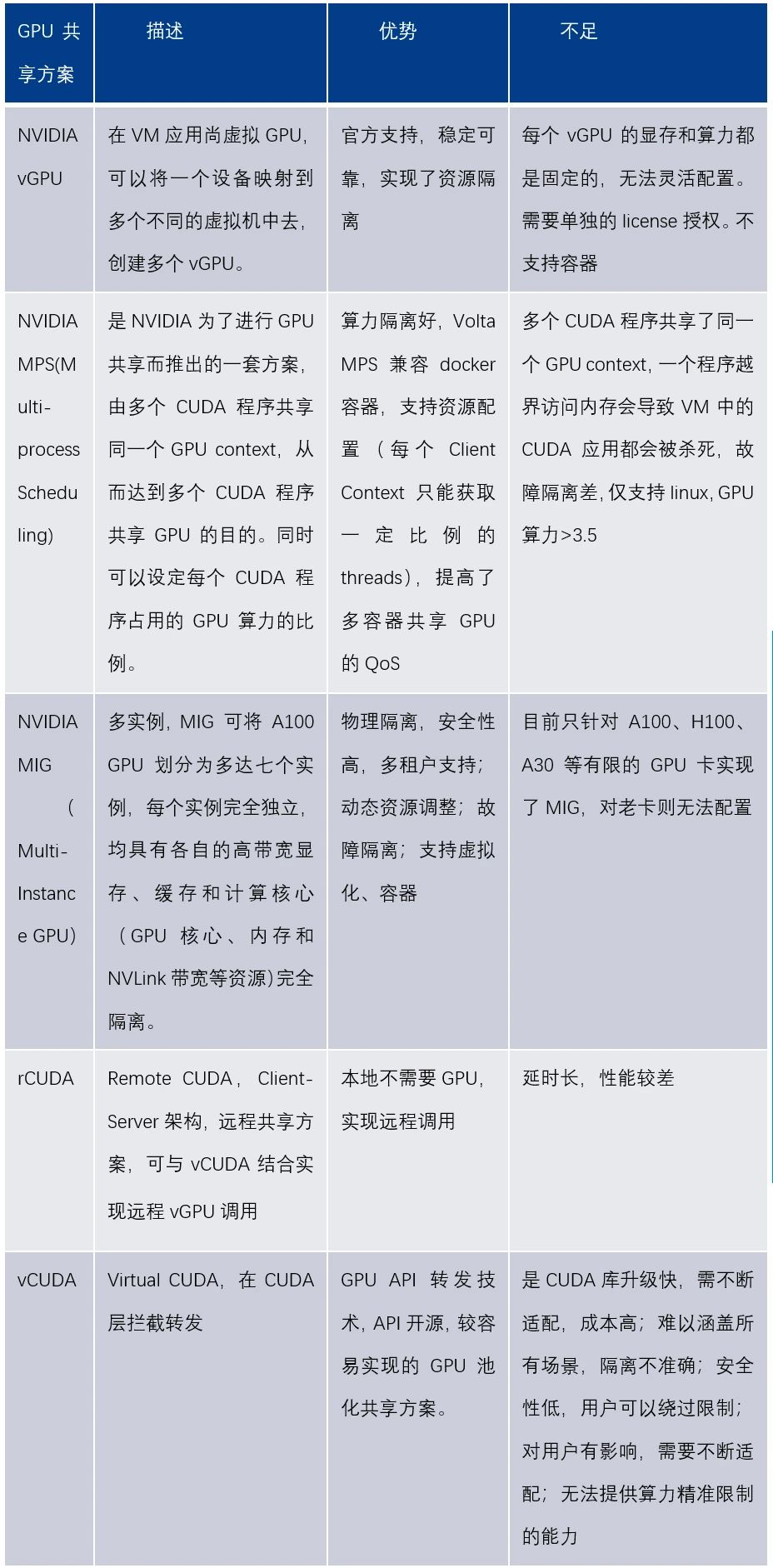
NVIDIA VGPU方案NVIDIA vGPU是NVIDIA提供的虛擬化方案,可靠性和安全性高,但不支援容器,只能虛擬化若干個vGPU ,使用不靈活;無法動態調整資源比例;有一定的共享損耗;不支援客製化開發,需支付額外license費用。 MIG方案MIG是多實例GPU方案。只支援Linux作業系統,需要CUDA11/R450或更高版本;支援MIG的卡有A100, H100 等比較高階的卡;支援裸機和容器,支援vGPU模式,一旦GPU卡設定了MIG後,就可以動態管理instance了,MIG設定時persistent 的,即使是reboot也不會受影響,直到使用者明確地切換。
借助MIG,用戶可以在單一GPU卡上獲得最多7倍的GPU資源,為研發人員提供了更多的資源和更高的靈活性。優化了GPU的利用率,並支援在單一GPU上同時執行推理、訓練和高效能運算(HPC)任務。每個MIG實例對於應用程式都像獨立GPU一樣運行,使其程式設計模型沒有變化,對開發者友好。
MPS(Multi-Process Scheduling)MPS多進程調度是CUDA應用程式介面的替代二進位相容實作。從Kepler的GP10 架構開始,NVIDIA 引入了MPS ,允許多個流(Stream)或CPU 的進程同時向GPU 發射K ernel 函數,結合為單一應用程式的上下文在GPU上運行,從而實現更好的GPU利用率。當使用MPS時,MPS Server會透過一個CUDA Context 管理GPU硬體資源,多個MPS Clients會將他們的任務透過MPS Server 傳入GPU ,從而越過了硬體時間分片調度的限制,使得他們的CUDA Kernels 實現真正意義上的並行。但MPS由於共享CUDA Context也帶來一個致命缺陷,其故障隔離差,如果一個在執行kernel的任務退出,和該任務共享share IPC和UVM的任務一會一同出錯退出。 rCUDArCUDA指remote CUDA,是遠端GPU呼叫方案,支援以透明的方式並發遠端使用CUDA 設備。 rCUDA提供了非GPU節點存取使用GPU 的方式,因此可以在非GPU 節點運行AI應用程式。 rCUDA是一種C/S架構,Client使用CUDA運行庫遠端呼叫Server上的GPU接口,Server監控請求並使用GPU執行請求,返回執行結果。
在實際場景中,無需為本地節點配置GPU資源,可以透過遠端呼叫GPU資源而無需關注GPU所在位置,是非常重要的能力,隔離了應用程式和GPU資源層。 vCUDAvCUDA採用在用戶層攔截和重定向CUDA API的方式,在VM中建立pGPU的邏輯映像,即vGPU,來實現GPU資源的細粒度劃分、重組和再利用,支援多機並發、掛起恢復等VM的高級特性。 vCUDA函式庫是nvidia-ml和libcuda函式庫的封裝函式庫,透過劫持容器內使用者程式的CUDA呼叫來限制目前容器內程序對GPU 算力和顯存的使用。 vCUDA優點是API開源,容易實現;缺點是CUDA庫升級快,CUDA 庫升級則需要不斷適配,成本高;另外隔離不準確無法提供算力精準限制的能力、安全性低用戶可以繞過限制等。目前市面上廠商基本上都是採用vCUDA API轉送的方式來實現GPU算力池化。
GPU算力池化雲端原生實現GPU池化(GPU-Pooling)是透過對實體GPU進行軟體定義,融合了GPU虛擬化、多卡聚合、遠端呼叫、動態釋放等多種能力,解決GPU使用效率低和彈性擴展差的問題。 GPU資源池化最理想的方案是屏蔽底層GPU異質資源細部(支援英偉達和國產各廠商GPU) ,分離上層AI 架構應用與底層GPU類型的耦合性。不過目前AI框架和GPU類型是緊密耦合的,尚沒有實現的方案抽像出一層能屏蔽異構GPU。
基於不同框架開發的應用程式在遷移到其他類型GPU時,必須重新建構應用,至少要遷移應用到另外的GPU,往往需要重新的適配與調試。算力隔離、故障隔離是GPU虛擬化與池化的關鍵。算力隔離有硬體隔離也就是空分的方式,MPS共享CUDA Context方式和Time Sharing時分的方式。越靠底層,隔離效果越好,如MIG硬體算力隔離方案,是一種硬體資源隔離、故障隔離方式,效果最好。但硬體設備程式介面和驅動介面往往是不公開的,所以對廠商依賴大,實施的難度非常大,靈活性差,如支援Ampere架構的A100等,最多只能切分為7個MIG實例等。 NVIDIA MPS是除MIG外,算力隔離最好的。
它將多個CUDA Context合併到一個CUDA Context中,省去Context Switch的開銷並在Context內部實現了算力隔離,但也致額外的故障傳播。 MIG和MPS優缺點都非常明顯,實際工程中使用的並不普遍。採用API轉送的多工GPU時間分片的實作模式相對容易實現且應用最廣。根據AI應用使用GPU的呼叫層次,可以實現不同層次的資源池化能力。例如CUDA層、Diver層、硬體設備層等。在不同的抽象層次,將需要加速的應用轉送(Forwarding)到GPU資源池。總的來說,越靠底層的轉發效能損失越小,可操作的範圍越大;但同時,程式設計量也越大,也越難。

由於雲端原生應用程式的大量部署,GPU算力資源池化需要支援雲端原生部署能力,比如說支援Kubernetes、Docker服務,透過K8s Pod綁定由GPU資源池按需虛擬出來的vGPU,執行Pod中的應用。不管是英偉達的GPU卡或是國產GPU,所有的卡片都在算力資源池中,目前可以將不同的卡片分類,不同框架的應用按需調度到適當的分類GPU算力池上。從而提升資源管理效率。算力資源池同樣需要實現對應的資源、資產管理和運作監控和可觀測性,優化調度能力,減少GPU資源片段。隨著AI應用需求的快速成長,算力資源池化在未來一段時間內將是企業關注的重要的一個面向。