標準化測驗適用於各級教育、多種評估環境以及多種目的。它們可以幫助教師、教育工作者、雇主和政策制定者做出有關學生、其他教師、求職者、員工甚至計畫和機構的決策。標準化測試必須提供公正且準確的數據、指標和信息,從而滿足最高的專業、技術和行業標準。
OpenEDG Python Institute 認證考試旨在衡量特定領域的知識、技能、能力以及執行特定任務的資格的熟練程度。同時,應提供公平、有效、可靠、可信、安全的資訊來源。
OpenEDG Python Institute 的考試和認證開發流程是嚴格、全面且協作的。我們採用細緻、諮詢驅動、能力導向的方法來進行測試設計、測試開發和測試實施,利用定性開發框架、以主題為中心的設計模式和心理測量建模機制。
考試開發過程由許多相互關聯的階段組成:
市場研究和分析—整個開發過程的基礎。考試和認證是按照嚴格的行業和市場研究流程設計和開發的,其中包括工作任務分析(JTA)、培訓需求分析(TNA)、技能差距分析(SGA) 以及進行的大量定性和定量研究,以確定雇主尋求的職位描述和實際技能工具包,以及學校教授的技能,以彌合教育部門和工業部門之間的差距,並確保認證持有者俱備他們追求和實現目標所需的所有必要手段。推動IT和程式設計領域的職業發展。
教學大綱制定– 此階段涉及招募SME(主題專家)來確定考試目標、確定目標受眾(工作任務分析和專業標準評估)、準備考試文件以及進行預先建構的初始過程考試結構和內容。SME 與協助考試開發和測試驗證流程的心理測量師進行協調。在OpenEDG Python Institute,我們與Python社群專家以及產業和教育部門代表密切合作,確保我們的認證和考試標準滿足市場的實際需求,並遵循「由專業人士製造,為專業人士服務」的原則。
考試設計和開發-最重要的階段,其中創建考試內容。它涉及認證專案經理、利害關係人、心理測量學家、中小企業、考試出版商和開發人員的同步合作,共同創建考試框架、結構、題目格式、交付模式和格式、評分以及設計實際考試專案。考試設計和開發階段由六個階段組成:
結構開發:定義測驗規格(藍圖),例如部分數量、項目數、考試長度、問題類型、評分模型、圖形或展示、簡報順序、報告組等。
專案開發:專案寫作、篩選、技術審查-定義主幹、正確答案和乾擾項;定義展品和圖形的要求;技術證明;
展示開發:建構補充考試項目的媒體、模擬和圖形;展覽實施;
校對:語言編輯、二次技術校對、掃描錯字;文案編輯;
物品選擇與實施:選擇將包含在物品池中的物品;建立原始檔案並在本地考試系統中實施以供內部審查;
Live Pool 部署和第一次內部審查- 考試在測試環境中組裝和部署。考試的第一次內部審核在模擬考試環境中進行;該考試由中小企業發起和測試;必要時立即進行更正和修改。此次審查的主要目的是在發布試點測試 (SMT) 考試之前找到並消除錯誤。
小市場試驗(SMT) – 在Beta 測試人員和焦點小組中進行考試的試點測試階段。考生還被要求對可能誤解、措辭不佳或沒有或超過預期正確答案的考試項目進行評分。
最終審查和評估– 深入了解各個考試項目的表現以及整個考試,其中包括研究以下方面:診斷項目難度級別的潛在問題、診斷考試項目之間的相關性、確定可能的評分並回答關鍵問題,確定對考試通過率和分配時間的假設估計。最終(修訂/更新)考試版本(操作項目池和最終規範的組合)是此階段的最終產品,現已準備好發布。
考試發布– 根據評估階段的結果設計、測試、評估和更新考試的階段,現在準備發布。該考試標有一系列程式碼,並透過 OpenEDG 測試服務 (TestNow™) 以及全球知名測試中心網路在全球範圍內提供。此階段需要產品經理和考試發布者之間的密切合作,以便流程有效、及時和成功。
考試維護– 考試設計和發展是一個持續的過程,因此一旦考試上線並且考生開始參加考試,就會發生考試維護階段。在此階段,將對考試的表現進行監控和分析,以確保其符合市場研究、市場分析和教學大綱開發階段中規定的目標和假設。收集到的數據可以進行發布後分析和考試更新,這意味著重新審視考試內容,並重新開始整個考試設計過程。在此過程中,我們會分析考生的體驗和考試聲譽,以便做出必要的改變,以改善測試體驗並增強認證計劃的可信度和認可度。考試更新頻率:首次發布後或在指定數量的考生參加考試後每兩年一次;以先發生者為準。
評估流程
OpenEDG Python 研究所根據教育和心理測驗標準(AERA、APA、NCME)以及歐洲測驗使用者標準和歐洲測驗中提出的有關教育和心理評估實踐的規定性指導對其考試進行驗證。測試評審模型(EFPA、EAWOP)。
評估過程包括對測試計劃的設計、開發和實施過程中收集的所有可用證據進行徹底審查,並涉及測試發布者、主題專家和心理測量學家之間的迭代合作。此外,也對現場受訪者在現場測試收集的數據進行了全面審查。因此,評估和測試實踐的驗證是以符合適用的行業最佳實踐、道德標準和著名研究文獻的方式進行的。出版商、主題專家和心理測量學家之間的迭代合作過程,以及證據與適用標準的比較,為調查結果和建議奠定了基礎。
項目反應理論 (IRT):驗證單維度
與傳統的固定形式考試相比,Python Institute 測試採用「隨機-隨機」抽樣程序,從項目測試庫中隨機抽取每個項目的多個版本之一。因此,不存在固定形式的考試版本,這有助於防止作弊和盜版。
專案級分析是在專案反應理論(IRT)的指導架構下進行的。與經典測驗理論(CTT) 相比,IRT 被認為是對新的和既定的測量進行心理測量評估的標準方法(如果不是首選方法)。在高層次上,IRT 的前提是,只有兩個因素決定一個人對任何給定項目的反應:人的能力(或多個能力)和項目的特徵。
Python Institute 考試的開發和驗證需要使用一維 IRT 模型,該模型的前提是測試問題的回答之間的相關性可以透過單一基本特徵(即 Python 熟練程度/能力)來解釋。雖然像 Python 熟練程度這樣的特徵/能力很複雜,代表了以特定方式組合的許多不同的組成技能和事實,但一維性的主張是這些組件一起工作以體現一個連貫的整體。儘管測試是圍繞四到六個主題部分構建的,但這樣做是為了提供足夠的領域抽樣,而不是為了測量不同的特徵。
雖然個人在單維度測驗的主題部分方面可能有優點和缺點,但這些主題部分之間的任何系統關係都應該透過單一潛在特徵或能力(Python 熟練程度)對考生項目反應的影響來解釋。根據文獻標準,透過使用驗證性因子分析(CFA) 模型和審查配適優度統計資料(RMSEA、CFI、TLI)來評估(和確認)一維性。
項目反應理論 (IRT):模型概述
在基本層面上,IRT 模型會估計數學方程,以便對考生正確回答某個項目的機率與其能力水平之間的關係進行建模。IRT模型的基本單位是項目特徵曲線(ICC),它根據人的潛在能力水平來估計給定響應的機率,其中曲線的形狀和位置由項目特徵估計的項目特徵決定。模型參數。雖然 IRT 模型可以採用多種不同的形式,但用於我們測試評估的 IRT 模型假設給定響應的機率是人的能力(theta θ)、項目的難度(a)項的歧視。
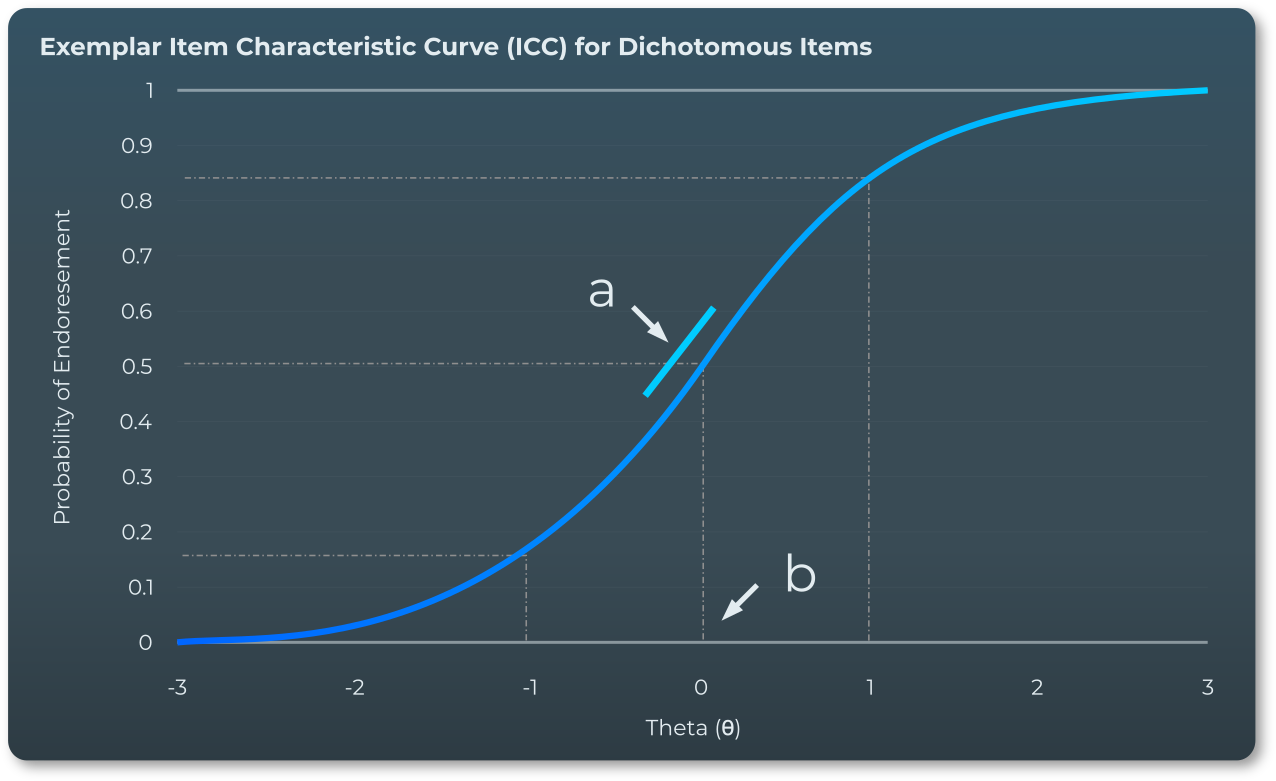
廣義部分信用模型
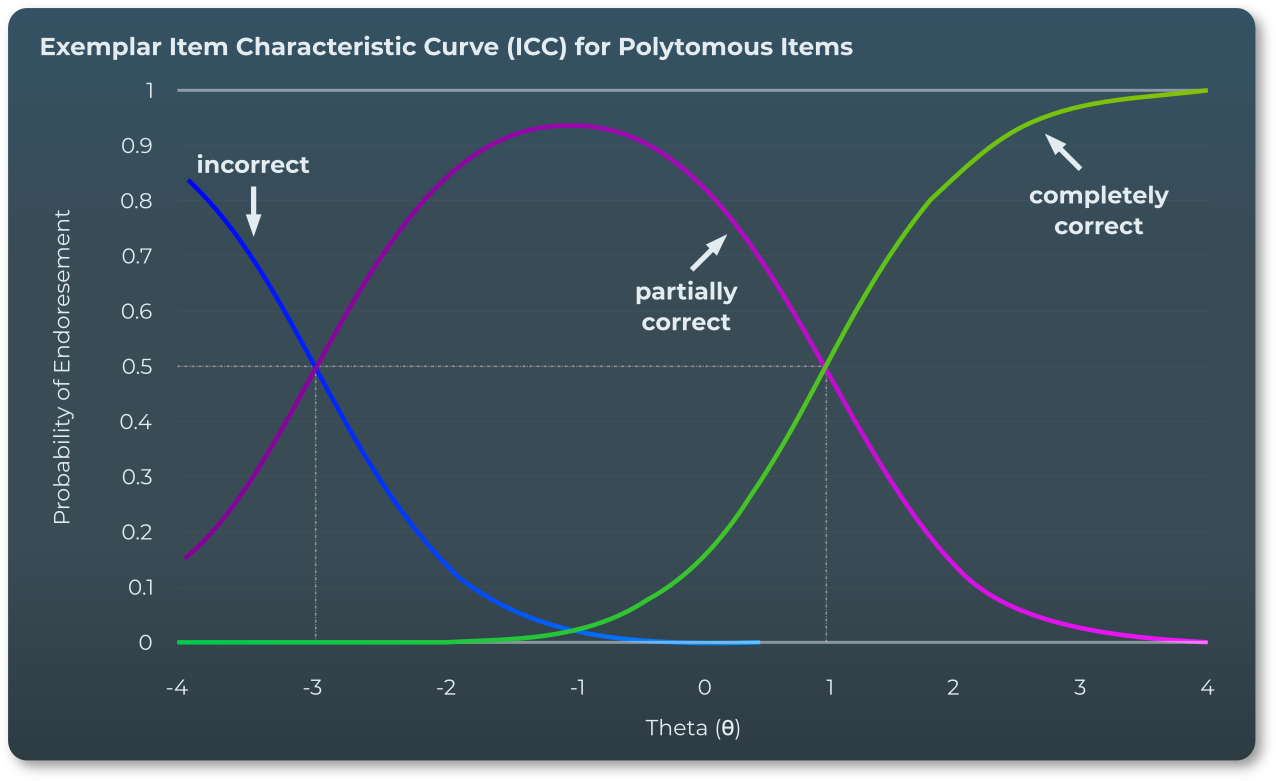
考試評估是利用特定形式的 IRT 模型(稱為廣義部分學分模型(GPCM))進行的,該模型允許混合二分項目(其中回答完全正確或完全錯誤)和多分項目(其中考生可以因部分正確的回答而獲得部分學分)。GPCM模型包含以下四個參數:
部分學分閾值的難度參數 (b 1 )
滿分閾值的難度參數 (b 2 )
辨別參數 (a) – 描述此題項區分能力的程度
人員層級能力參數 (θ) – 考生能力水準的標準化衡量標準
專案資訊功能(IIF)
可以使用項目資訊函數– IIF 或 I(θ) 在 IRT 模型中評估項目和測試提供的資訊。項目的資訊本質上是項目在能力水準 (θ) 範圍內的精確度或準確度的指數。如果某個項目對於給定能力水平的個人來說非常精確和準確,那麼該項目就該能力水平提供了非常豐富的資訊。項目資訊函數圖基本上提供了這一點的直觀表示,使得 IIF 曲線上的最高點對應於項目資訊最多的能力水平。
此外,IIF 圖的峰值也很有用,因為具有陡峭、狹窄、峰值 IIF 曲線的項目表示該項目在特定能力範圍內資訊豐富。相較之下,淺的、峰值較小的 IIF 曲線表示在更廣泛的能力水準範圍內分佈的資訊量較少的項目。
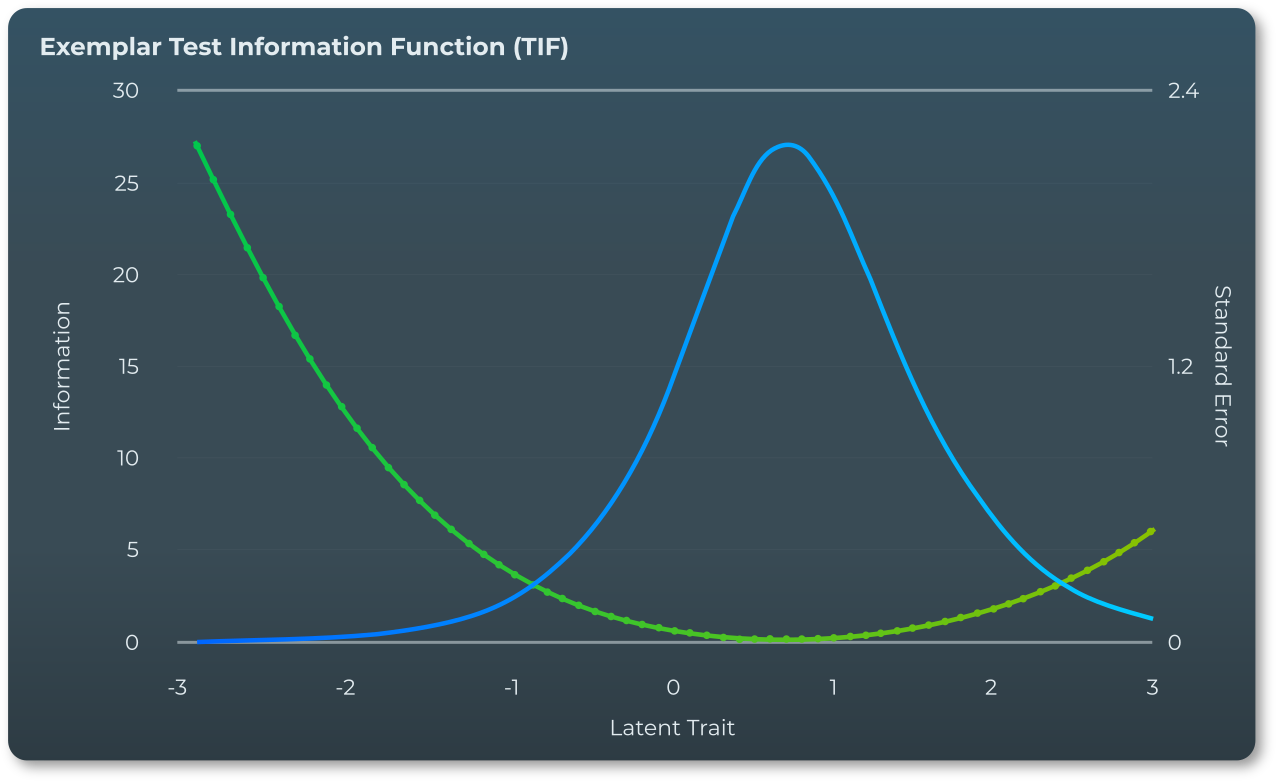
項目資訊函數(IIF) 代表每個單獨項目資訊最豐富的能力等級範圍,而測試資訊函數(TIF) 則代表整個測試資訊最豐富的能力等級範圍,以及它的功能最有效。正如項目資訊函數與給定單一項目在不同能力水平上的精確程度相關一樣,測試資訊函數與測試在不同能力水平上的精確程度相關。
這種整體準確度和精確度透過θ 標準誤差的倒數進行索引,它簡單地量化了沿能力水平 (θ) 範圍內任何估計的預期誤差。實際上,當 TIF 曲線集中在低於平均能力水準 (θ < 0) 時,測試最有效,並為能力水準較低的個人提供最低標準誤差的估計。當 TIF 集中(達到峰值)於較高的能力水平 (θ > 0) 時,這表明整個測試在評估高於平均水平的能力水平方面最有效。
发表回复